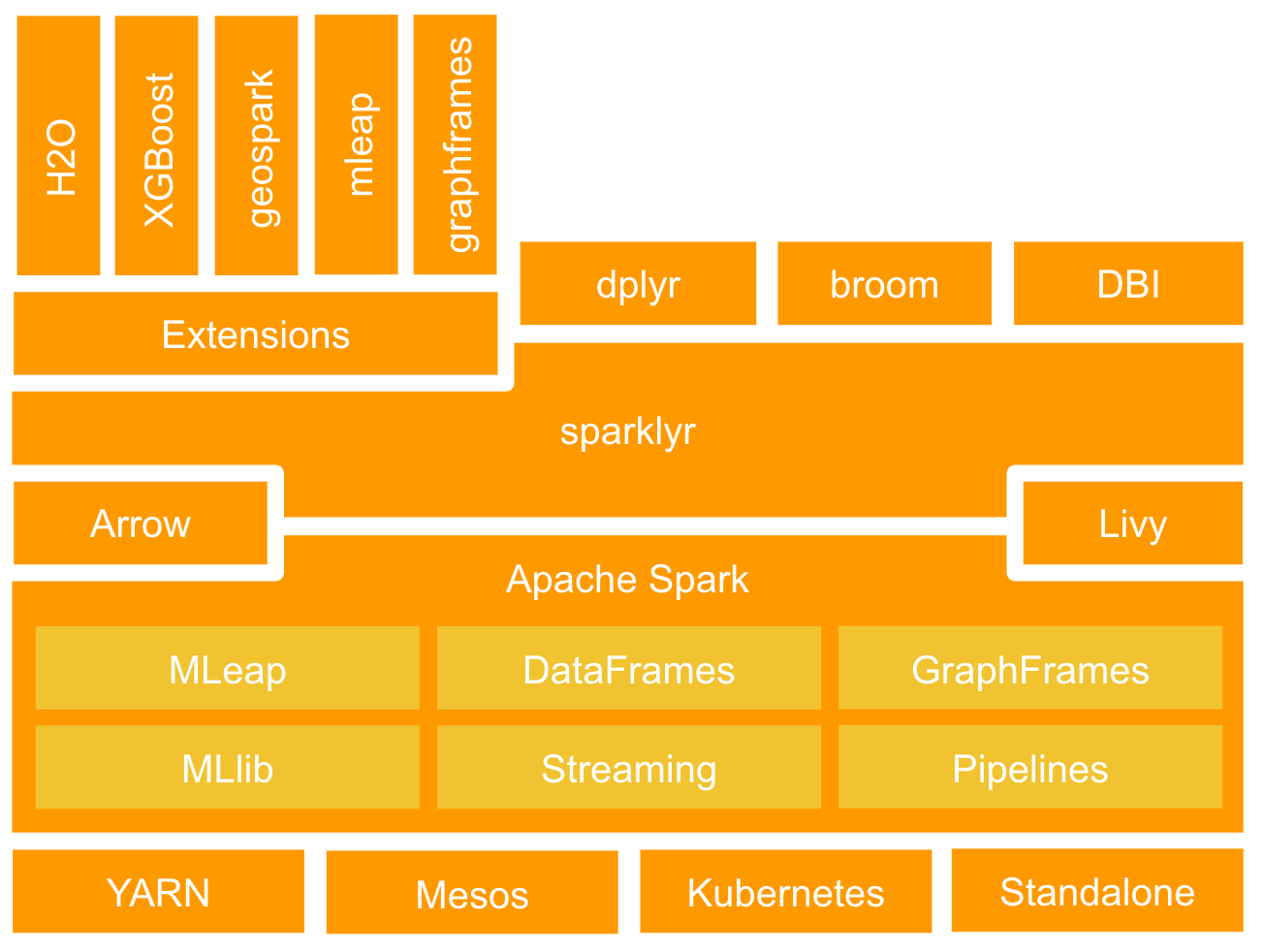
sparklyr is an open-source and modern interface to scale data science and machine learning workflows using Apache Spark™, R, and a rich extension ecosystem.
It enables using Apache Spark with ease using R by providing access to core functionality like installing, connecting and managing Spark and using Spark’s MLlib, Spark Structured Streaming and Spark Pipelines from R.
Supports well-known R packages like dplyr, DBI and broom to reduce the cognitive overhead from having to re-learn libraries.
And enables a rich-ecosystem of extensions to use in Spark and R: XGBoost, MLeap, GraphFrames, H2O, and optionally enable Apache Arrow to significantly improve performance.
Through Spark, this allows you to scale your Data Science workflows in Hadoop YARN, Mesos, Kubernetes or Apache Livy.